25 Mar
So, you are dying to run an A/B test on that one site/product/app/feature you think you can improve. But the user traffic is so low that it seems to be statistically unfeasible to run the test.
Has this situation ever happened to you? If not, I’m sure it still will. But don’t worry. Keep reading this post for what to do in these scenarios.
Unfortunately, a very common limitation for those who want to run an A/B test is the number of participants available. In other words, the traffic visiting whatever it is you are running the test on — web page, feature, etc.
This happens because, as in any serious scientific experiment, an A/B test needs a minimum number of participants — or traffic — in order to achieve reliable results. Otherwise, you may end up drawing conclusions based merely on chance. A simple matter of the luck of the draw.
What Makes for a “Reliable” Test Result?
It is not my goal in this article to go into statistical details (considering I’m not even a statistician). But in a few moments, I’ll be forced to mention a few vital concepts in order to prevent atrocities in experiments.
One of these concepts is statistical significance. This is a number that is typically expressed in A/B testing tools as a percentage, ranging from 0 to 100%.
The significance determines a percentage value to how likely it is that the difference between conversion rates for Control (“A”) and Variation (“B”), identified during A/B testing, is “real,” as opposed to mere happenstance.
(The concept is technically a little more tedious than that. But it’s not essential to this particular article.)
Certain industry standards tend to consider a test result as “reliable” when its statistical significance is equal to or greater than 95%. This means there is a 5% chance of the result being just a matter of luck … or lack thereof.
How Much Traffic Do You Actually Need to Run a Reliable A/B Test?
This is a classic question that warrants the usual discouraging response: it depends.
There is no exact number of visitors required to run A/B tests with reliable results. This is because the number of people required for a test depends on several variables.
Let me explain the main ones — with examples:
1. Conversion Rate
The higher the conversion rate you want to optimize, the less traffic you’ll ultimately need in order to run your test.
Check out this example using the VWO Calculator:
The page we want to optimize has 1,000 daily visits and a conversion rate of 2%. In the scenario shown (which has another important variable I will explain below), we would need 103 days (or 103K visitors) to arrive at a reliable result. An eternity!
But check out what happens when we optimize a page with a conversion rate of 10%:

Simply because it’s a page with a higher conversion rate, the test duration (i.e., the amount of visits it needs to tally up) dropped drastically to 29 days (29K visitors).
2. The Difference Between A and B
The greater the difference in conversion rate between A and B, the fewer the required visits to achieve a statistically significant result. Let’s take another example.
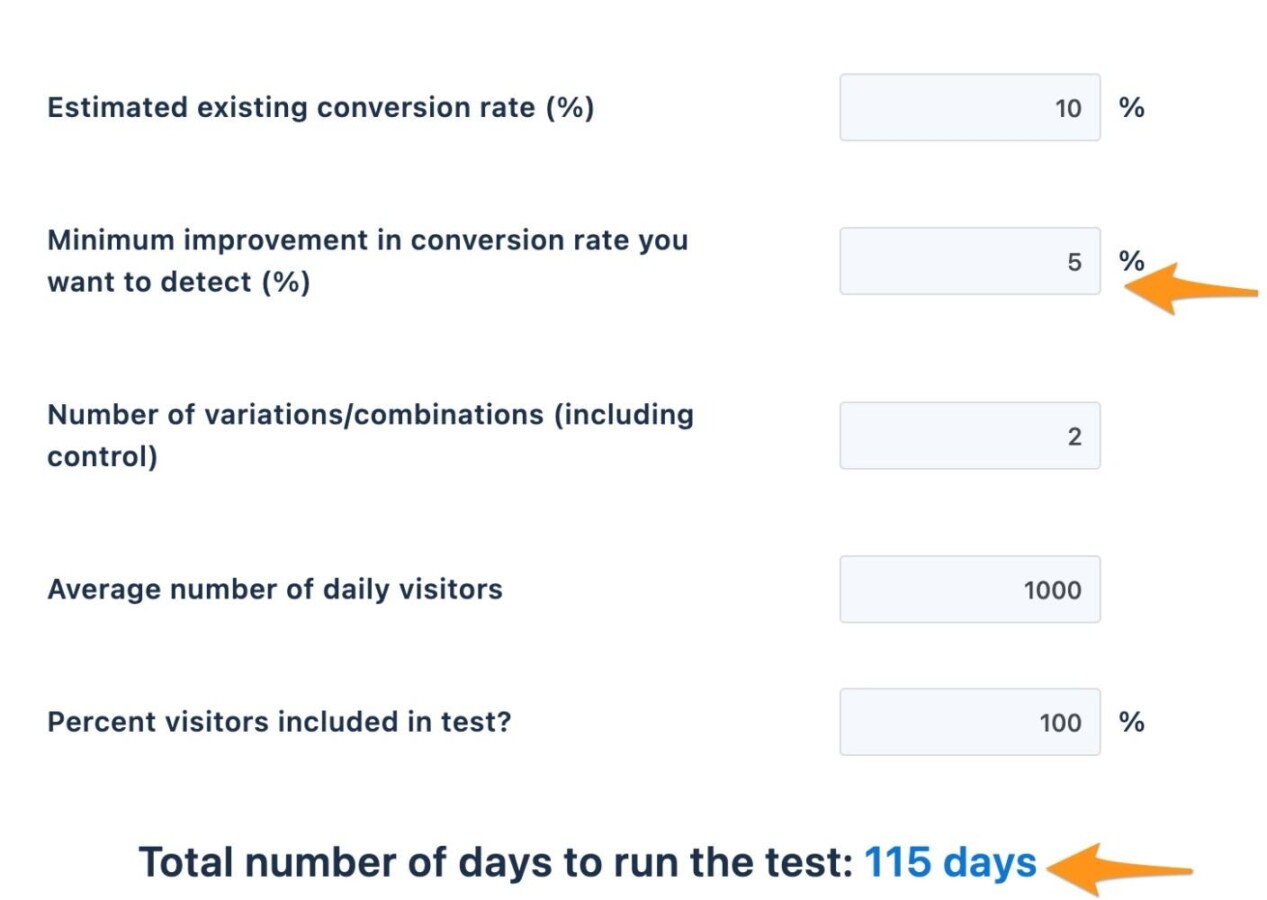
Note the line, “Minimum improvement in conversion rate you want to detect“:

The “10%” means that the Test Variation needs to increase its conversion rate by at least 10% over the original page for the test to achieve a reliable result in the above scenario. Any improvement below 10% will not be detected with statistical validity in the same period (or with the same amount of traffic).
Here’s how things change when we want to be able to detect a 5% increase in conversion rate:

The time required for this test increases from 29 to 115 days (115K visitors).
On the other hand, if we are only interested in being able to detect conversion increases of 20% or more, here’s what happens to the time/traffic required:

That’s right. If we increase conversion by 20%, we need only 7 days to get a result with high statistical significance.
Therefore, the level of fine detail you choose to have in detecting a conversion rate improvement is an important factor to determine the feasibility of running a test.
Below, we will touch more on how to use this variable wisely.
3. Statistical Significance
Further up, I said that our industry considers a statistical significance to be “reliable” (the chance of the outcome not being pure luck/misfortune) at 95%.
But it is important to say that the 95% rate is nothing more than a “common agreement.” There is nothing magical about it and you should not observe it blindly. For instance, some of the world’s best testing companies are more than happy with most of their tests that have a significance of 90%, or even less.
It all depends on how much risk you want to take by relying on the test results. Often, the opportunity cost is too high to expect to reach a significance level of 95%.
But if you are running a test that will inform a very strategic decision for the company, perhaps you’ll want a higher statistical significance.
In other words, if you are testing the copy of an ad, you have a certain tolerance for risk. If you are testing a new type of cancer diagnosis, your tolerance changes. 95% significance is only a benchmark, but it has some flexibility.
OK. It Depends. But Is There a Reference Point?
I hope the exercises above have shown you how much the traffic required for a test can vary. On the same test, we calculated a range between 115 thousand and less than 7 thousand visitors.
I know that the answer “depends” doesn’t appease anyone. So, I’ll give you a general reference point: a test tends to be viable on interfaces that can deliver at least a few thousand monthly visits and 100 conversions per version (A, B, C, etc.).
But again, the best route is to use a calculator like the one I showed you and assess your specific scenario.
Not Everyone Can Run A/B Tests. But Everyone Can Do CRO.
As we have seen, not everyone (and not every area of a site/product) is ready for A/B tests. But please don’t confuse things.
The fact that you cannot run an A/B Test does NOT mean that you cannot do CRO.
CRO’s entire diagnosis process and best practices for building hypotheses and improving interfaces apply just the same. The only difference is that in the end you will not have the ease of validating the result with an A/B test.
Is it ideal to be able to run the test? Of course. I won’t lie. As I have shown in previous issues of this newsletter, absolutely no method is as accurate as the A/B test when it comes to evaluating the outcomes of a change.
But there are some interesting strategies you can use to work around the apparent unfeasibility of an A/B test.
Let’s finally get to them!
Strategy for Low Traffic #1:
Leverage Your Top of Funnel Conversions
In the best of worlds, you’ll run experiments that measure the impact on the most profitable metric possible. For example, in e-commerce, this metric would be the revenue or the number of transactions. On a lead generation site, it could be something like the number of completed forms or qualified leads.
But here’s the problem: The deeper the conversion is into the funnel, the less it happens. And the lower the amount of conversions — you know it — the harder it is to run a reliable test.
Having fewer deep-funnel conversions is no reason not to run tests though. You can still reap various benefits from running tests that measure previous stages of the funnel, where the number of conversions is naturally higher.
There is nothing wrong with an e-commerce site that cannot run tests for transactions using “adds to cart” or “starts checkout” metrics as a goal.

Even though it is not the perfect scenario, there is usually a significant correlation between conversion increase in a stage of the funnel and its subsequent stages.
Strategy for Low Traffic #2:
Use the Minimum Amount of Variants Possible
When we are excitedly putting together a new web page version for an A/B test, it is very common for variation ideas to come up, quickly turning the A/B test into an A/B/C, A/B/C/D, A/B/C/D/E/F/G… Z test. Right?
After all… Wouldn’t the blue button you’re making look better in purple? And the image below, wouldn’t it be better in versions X or Y? And so on.
Many people who have worked with me know that I always insist on getting away from that temptation. The reason is simple.
The more variations, the more traffic it takes for a test to achieve statistical significance.
On the simple table below, check out how much traffic is required to achieve 95% statistical significance for a 10% increase on a site with a 5% conversion rate:
| Versions being tested | Traffic needed for 95% significance |
| 2 (A/B) | 61,000 |
| 3 (A/B/C) | 91,000 |
| 4 (A/B/C/D) | 122,000 |
The changes between versions X, Y, and Z of the new page are typically minor and do not represent any relevant improvement in the outcome for 99.9% of all sites.
If your traffic is low, always consider using this strategy. Do your best to limit your tests to just two versions: the original and the variant.
Obviously, sometimes there are excellent reasons to run an A/B/C or A/B/C/D test. For example, when there really is a significant difference in the user experience between the different versions of the variation.
However, note that in most cases — adding more variants to an A/B test is usually a waste of time and money.
Strategy for Low Traffic #3:
Increase Your Chances with Solid Reasoning
On a site with low traffic, you can’t “pull a Booking.com” and run 1,000 simultaneous tests. Your pace will need to be slower.
And since you won’t be able to run many tests throughout the year, each one of them is important.
Therefore, try to ensure that your test ideas are supported by reliable Analytics data or user interviews, surveys, etc. This will increase the chances that each of your tests will bring positive results.
Not that a failing test is a horrible thing.
Often, when these tests are well run, and even when they fail, they may bring more valuable insights than many winning tests. But if you run just a few tests a year, you really can’t afford to have 90% of your tests fail.
Strategy for Low Traffic #4:
Run More Aggressive Tests
With little traffic, you can’t afford to run tests with minor changes that will increase conversion by just 0.5 or 1%.
Remember that the lower the impact on the conversion rate, the more traffic is required to achieve statistical significance. So be bold and test more aggressive changes.
It’s a lot of fun to see cases where Google or Facebook simply changed a button from color X to color Y and managed to increase conversion. But on a smaller site, if you run this type of test, it is very likely that you won’t be able to identify any change.
(Unless the current color of your button is actually making the user experience difficult, which is usually not the case. It’s usually an argument like color psychology that leads to future inconclusive tests.)
The impact will be too small to identify with statistical significance.
Instead, combine Strategy #3 with this one. Identify the issues or uncertainties that are causing your visitors not to convert. Try to solve them with changes that actually try to be impactful enough to convert someone who previously wouldn’t make a purchase.
With this strategy, when you really get it right, the odds of making a considerable impact on the conversion rate (that is, reaching statistical significance) is much higher.
Strategy for Low Traffic #5:
Validate Your Changes Qualitatively
If your traffic is so low that you can’t run a test even after implementing the ideas above, you can borrow an alternative exercise from the Product Discovery teams.
Create your Variant and recruit a few users to go through it as if in a Usability Test. Check if what you planned for really happens with these users. Ask detailed questions about their experiences.
Another slightly more scalable option is to publish your Variant in an A/B test with the objective of having some users go through it. This way, you can record their interaction with the page through Analytics tools (such as Google Analytics) and Session Recording (such as Hotjar).
The test still won’t reach statistical significance, but you’ll have a good number of user interactions with the new page to try to gather insights.
It is important to make it extremely clear that these two methods pale in comparison to A/B tests in terms of accuracy and reliability.
If you don’t have enough traffic for tests, following these methods is much more efficient than simply publishing your changes and hoping they work out.
Strategy for Low Traffic #6:
Reconsider an Acceptable Statistical Significance
As we’ve seen above, a statistical significance level of 95% is an industry “standard”, but it’s not magical. You don’t have to adhere to it blindly.
In practice, the rule you must follow to make decisions regarding test results is this: The lower the statistical significance, the greater the risk of the result being due to mere chance.
In a broad sense, if a winning Variant of yours reached a significance level of 80%, the odds of having a “false” result are 20%. If you’re comfortable with that risk, go for it! Acknowledge the winning Variant, publish it permanently, and move on to the next test!
In Conclusion
By following the strategies in this article, many websites, products, and segments that at first glance seem “untestable” may go on to use Experimentation to improve performance in a much more data-driven way, rather than simply making changes and seeing what happens.
If, like most people, your traffic doesn’t hold a candle to the virtually infinite traffic of Big Techs, try to identify what you need to do to get as close as possible to the scientific method in your experiments.
You will often come up with solutions that go a long way in helping you make smart decisions, even though they’re not always a “gold standard” test (A/B test, randomized control trial). Respect the scientist within.
Additional CRO Resources
Keep reading about UX, experimentation and testing from Seer:
Looking for an Agency Partner?
Get in touch with my team at Seer to discuss how Conversion Rate Optimization can drive revenue, improve conversion rates, and more.
CONTACT US VIEW CASE STUDIES
Sign up for our newsletter for more CRO posts in your inbox:
Source: www.seerinteractive.com, originally published on 2022-03-25 14:01:10

![How to Successfully Use Social Media: A Small Business Guide for Beginners [Infographic]](https://b2webstudios.com/storage/2023/02/How-to-Successfully-Use-Social-Media-A-Small-Business-Guide-85x70.jpg)



![How to Successfully Use Social Media: A Small Business Guide for Beginners [Infographic]](https://b2webstudios.com/storage/2023/02/How-to-Successfully-Use-Social-Media-A-Small-Business-Guide-300x169.jpg)

Recent Comments