25 Apr
What is Google Cache?
Google cache is a feature of Google search that provides copies of web pages that are available to searchers independent of the live pages on the original website. Google makes a copy of the web page at a certain moment in time and serves that copy of the webpage if requested by the user.
Why Does Google Cache Pages?
Google caches pages primarily to allow them to be accessible to searchers even if the website is down. For example, if seerinteractive.com was down, you could still view a cached version of seerinteractive.com through Google search.
How Does Google Cache Pages?
Google caches pages by crawling a web page, storing its HTML in a database, and then rendering that HTML for the cached version of the page when requested. Google says they do not create a cached version of a webpage every time it is crawled though.
💡 Related: What is Crawl Budget & Why Does it Matter for SEO?
What is a Cached Page?
A cached page is the result of Google’s rendering of its stored HTML for the page it crawled at that time.
It is important to keep in mind that a cached version of a page is a snapshot of that page at that exact moment in time. If Google creates a cached version of your page on Monday and your site changes on Tuesday, the cached version will not reflect those changes. Changes will only appear when Google crawls your site again and decides it is going to take another snapshot of that page at that time.
Another thing to keep in mind is that Google is primarily rendering HTML for the cached version of a page. Javascript-dependent elements may not be included in the cached version of the page, depending on when the javascript was executed compared to when the HTML was rendered.
Why Google’s Cache is Important for SEO
You can use Google cache to get an idea of what content Google can see and crawl when they land on a webpage. This is very important when trying to determine whether elements on a site are visible to googlebot for indexation purposes.
How Do You View Cached Pages in Google?
Method 1
You can use Google.com to view cached pages by taking the following steps:
1) Go to google.com
2) Type a search query or domain into the search field to search for the page
3) Click the three-dot menu to the right of the domain URL
Click the three dots menu to access the About this result feature
4) Look for a bubble in the pop-up window that says “Cached” and click it.

Click the “Cached” button. If there is no “Cached” button the page isn’t cached.
5) This will load the cached version of the web page.

A rendered cached copy of seerinteractive.com
Method 2
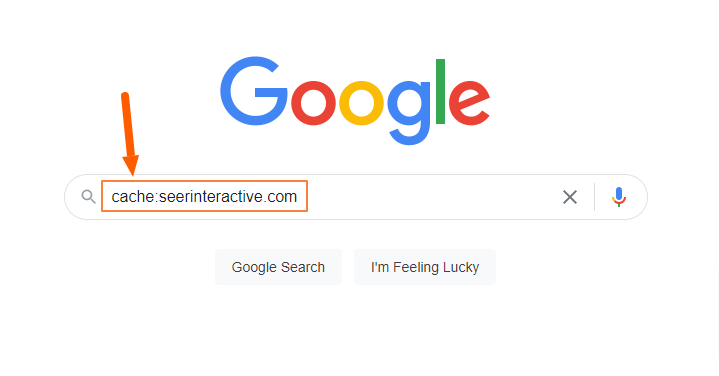
You can also search for cached versions of a specific URL using the “cache:” search operator.
To do this, follow the steps below:
1) Navigate to google.com or use the Chrome search bar
2) Type cache: and the URL you want to see the cached version of

Another way to view cached pages in Google.
3) Once you hit enter, the cached version of the page will automatically load
You’ll find the same information on the cached version of the page regardless of which method you use.
Understanding the Cached Page
You’ll notice that once the cached page loads the URL, there are additional parameters tacked on.
For our example, the cached URL is: https://webcache.googleusercontent.com/search?q=cache:3fOW-r47N58J:https://www.seerinteractive.com/+&cd=1&hl=en&ct=clnk&gl=us

Parameters used to fetch a page from Google’s cache.
These parameters are used by Google to fetch the cached page. They can be mostly ignored as they provide no useful information.
You can also see information related to the cached version of this page in the gray box at the top of the page.

This is a snapshot of the page
In this area, you can see the day and exact time the page was cached. At the time of writing this, the page was cached on 3/10/2022 at 12:40:10 GMT.
When viewing a cached version of a page you can use three different “views” to see different parts of the page.

Three different views of the cached page.
The first view is what is loaded by default, this is the Full version.
This includes the rendered page at the moment Google cached it. It includes all style and HTML elements.

Full version
The next view is a Text-only version.
This is a version of the page with no styling, it only shows the text on the page.

Text-only view
Finally, you can use the View source option to view the full source code of the page.

Source view
Things to Keep In Mind
Why is There No Cached Version of a Page?
Not all pages will be cached by Google.
Pages that rely on Javascript might not get cached, and if they do they could be blank if no HTML loaded while the snapshot was taken.
Google is not going to cache every page it crawls, so some pages you check might not have any cached version. This doesn’t mean the page wasn’t crawled, but Google can’t cache every page it crawls. It also doesn’t mean the page won’t ever get cached; it just hasn’t yet.
Some webpages won’t be cached because they ask Googlebot to not cache the page using a robots tag:
<META NAME=”GOOGLEBOT” CONTENT=”NOARCHIVE”>
💡 Related: How to Read Robots.txt
Cached Pages Are Not a Log File Replacement
Google’s cache isn’t a good metric to use to ensure Googlebot is crawling your site. Since Google won’t create a cached version every time it visits the site, you shouldn’t rely on the cached page date as an indicator of the last time Google crawled your site.
You are much better off relying on a website’s log files, if you have access to them, to determine when Googlebot last crawled a page.
Sign up for our newsletter for more posts like this in your inbox:
Source: www.seerinteractive.com, originally published on 2022-04-25 12:44:55

![How to Successfully Use Social Media: A Small Business Guide for Beginners [Infographic]](https://b2webstudios.com/storage/2023/02/How-to-Successfully-Use-Social-Media-A-Small-Business-Guide-85x70.jpg)



![How to Successfully Use Social Media: A Small Business Guide for Beginners [Infographic]](https://b2webstudios.com/storage/2023/02/How-to-Successfully-Use-Social-Media-A-Small-Business-Guide-300x169.jpg)

Recent Comments