29 Apr

The web is constantly changing, and pages get removed or redirected. This makes links to these pages go to a broken page or possibly a page that’s not like the original. This phenomenon is called link rot.
Since January 2013, 66.5% of the links pointing to the 2,062,173 websites we sampled have rotted. We found another 6.45% with temporary errors. We don’t know if they’re still there or not.
This is even more complicated when it comes to SEO. Another 1.55% have other issues that prevent the links from being counted for the purposes of ranking.
That means a total of 74.5% of the links in our study are considered lost, with at least 66.5% being rotted.
Often, the links that no longer work are important. Check out this example of a website that was referenced in a U.S. Supreme Court case. Someone bought the domain and used it to make a statement.

In a previous study of legal journals and citations from 2014, 70% of the links within the journals and 50% of the URLs from U.S. Supreme Court decisions did not contain the originally cited material.
Another study from 2012 found that 30% of social media links were dead within two years.
Most of the previous studies are fairly small and contain older parts of the web. I assume a lot more of the older web is already gone, if not most of it. For example, most sites stopped using extensions like .html on URLs many years ago in favor of clean URLs. Most sites have also moved from HTTP to HTTPs.
Considering the above, we decided to do the largest link rot study ever. And it’s one of the only ones that cover the more recent version of the web.
Let’s dig into the data.
About the data
Ahrefs has been crawling the web since 2010. But for the purpose of this study, we’re only looking at the data from January 2013.
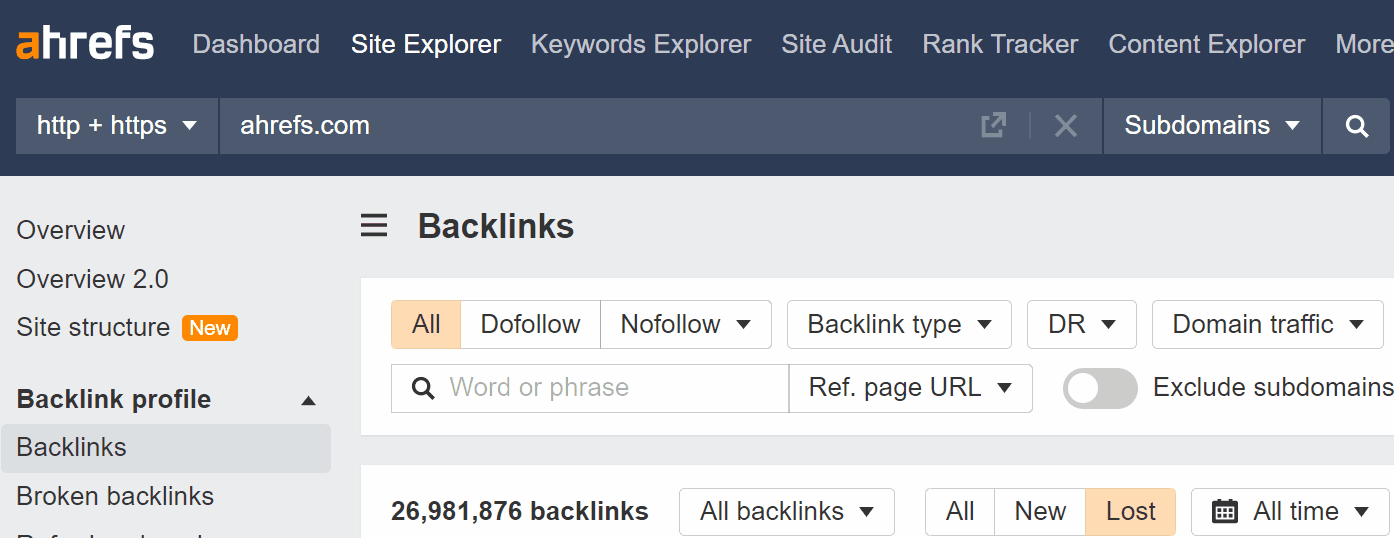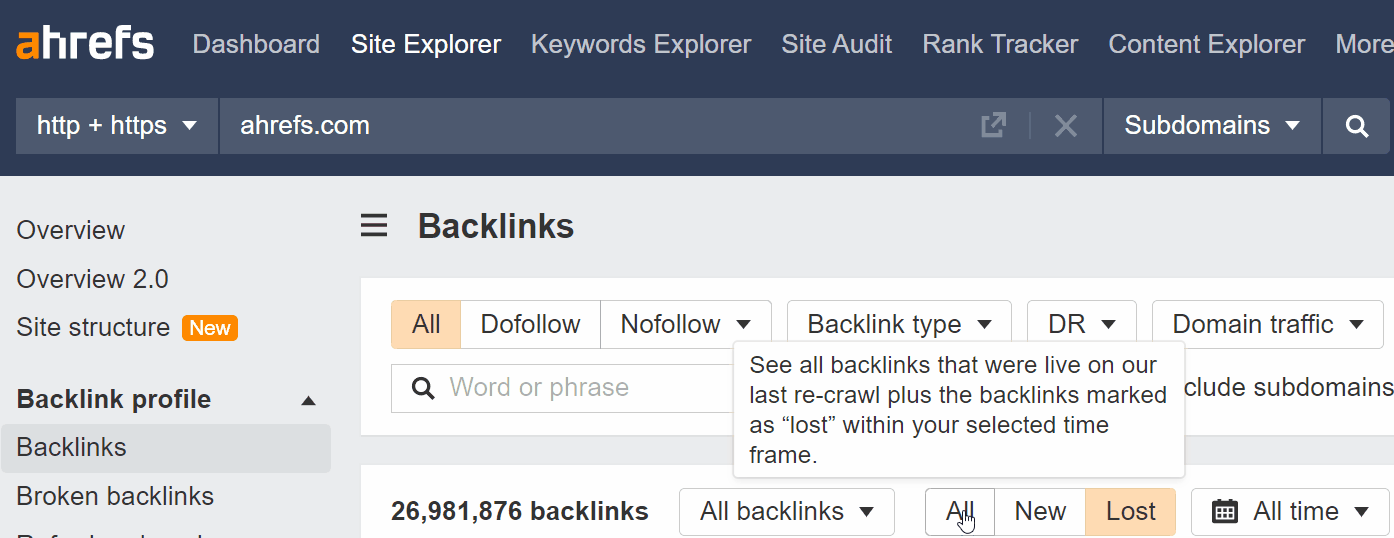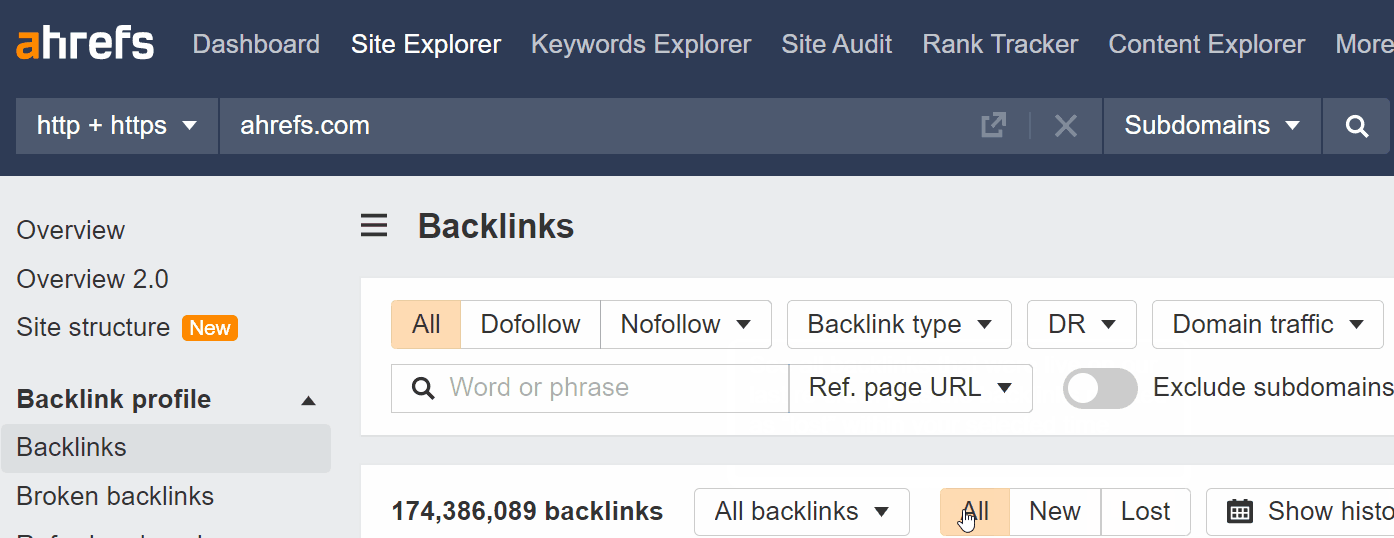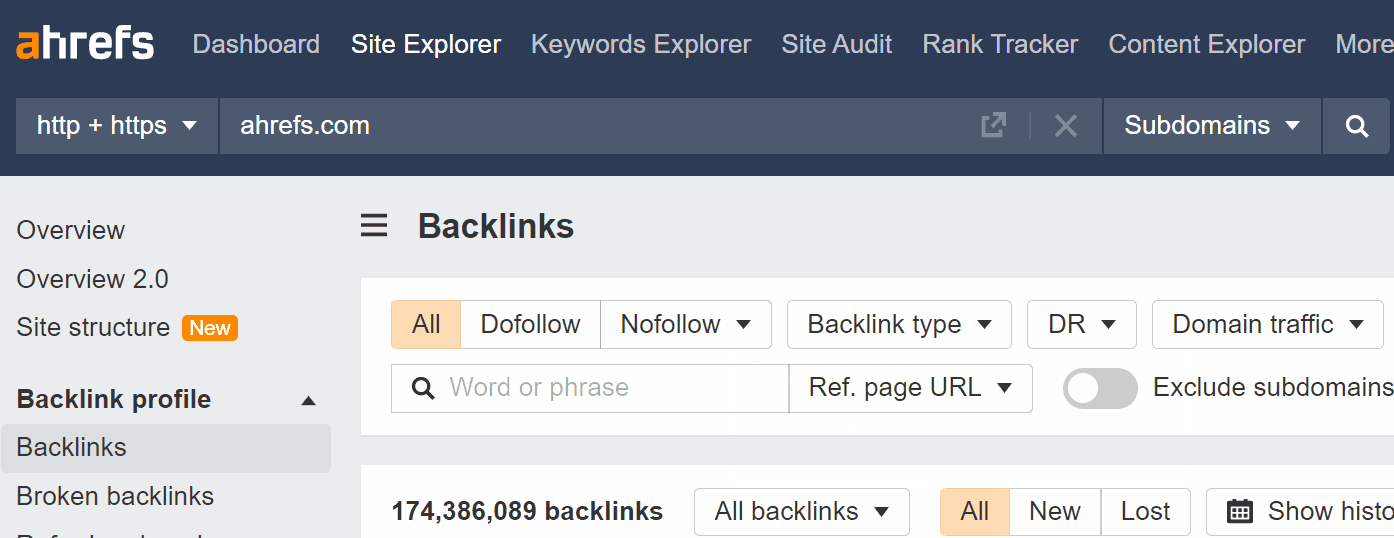
You can use the Backlinks report in Ahrefs’ Site Explorer to check the data for your own site. For Ahrefs, 26.9 million out of 174.3 million links have been lost. Just compare the numbers with the “Lost” filter applied vs. the numbers with the “All” filter applied.
There are a few cases we tag as lost that we don’t count as link rot. I’ll cover that below.
As I mentioned in the intro, at least 66.5% of links to the sampled websites have rotted in the last nine years.
The web is complex and messy, and some things change faster than others. I wanted to see how many sites have link rot—and what percentage of their links experience link rot. This is the distribution for the percentage of link rot by domain across the dataset.
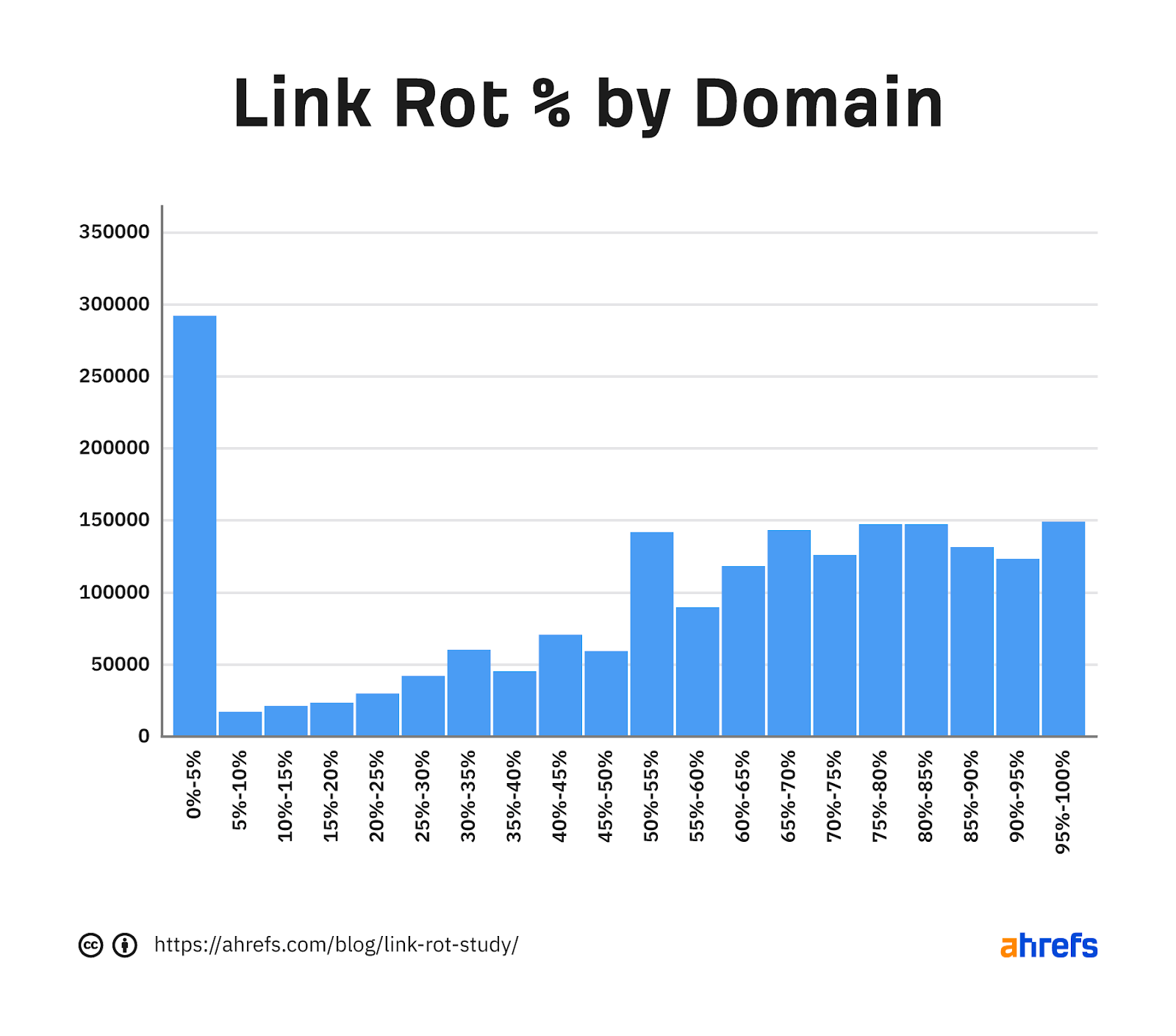
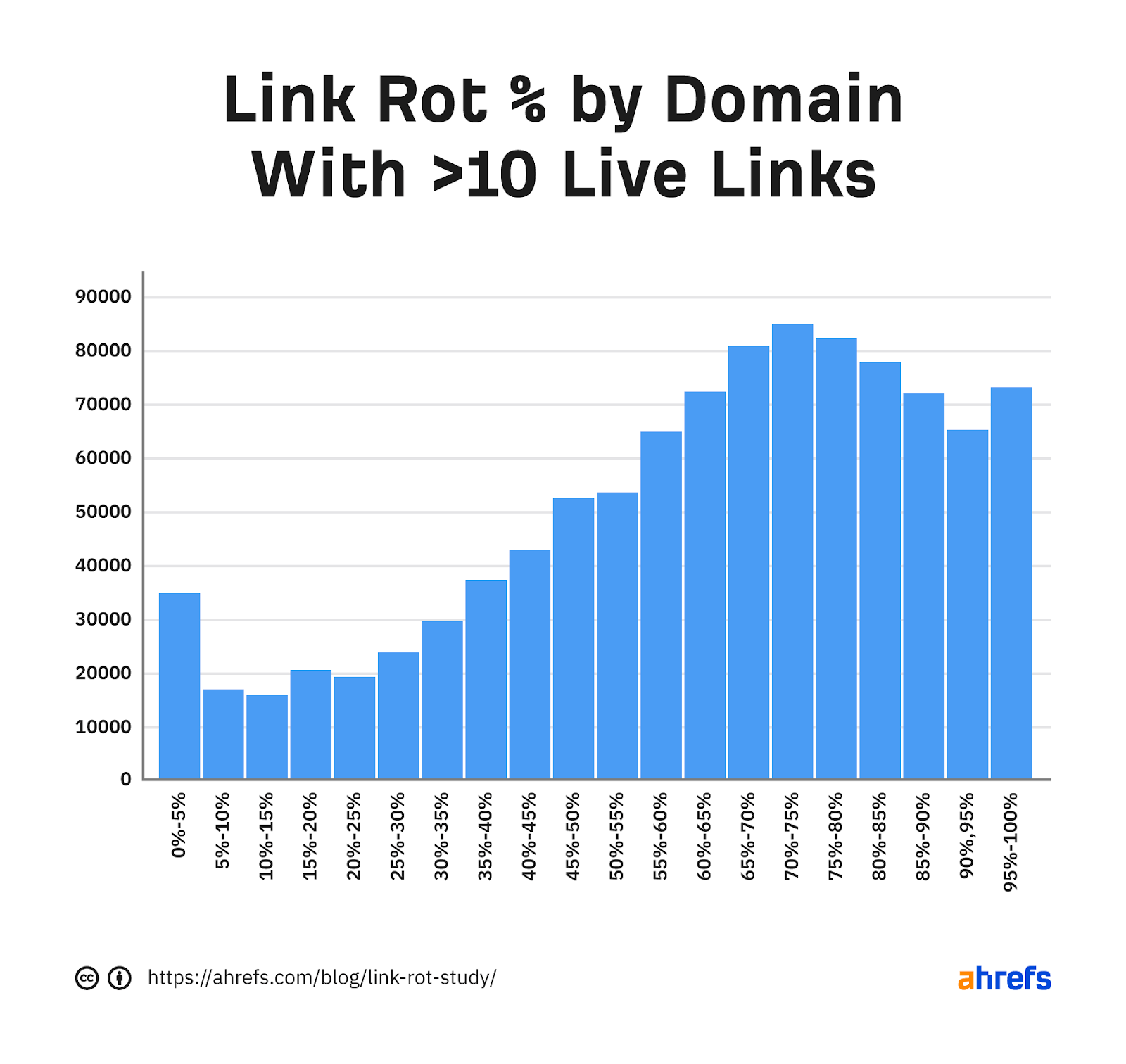
There are a lot of small sites that don’t have much link rot. If we take out the smallest sites and only look at those with more than 10 live links, you’ll see that larger sites seem to have quite a bit of link rot.
As I mentioned in the intro, the number of links we consider lost when it comes to SEO is even higher—percentage-wise, it’s 74.5%. I also wanted to see the distribution for these across the dataset.
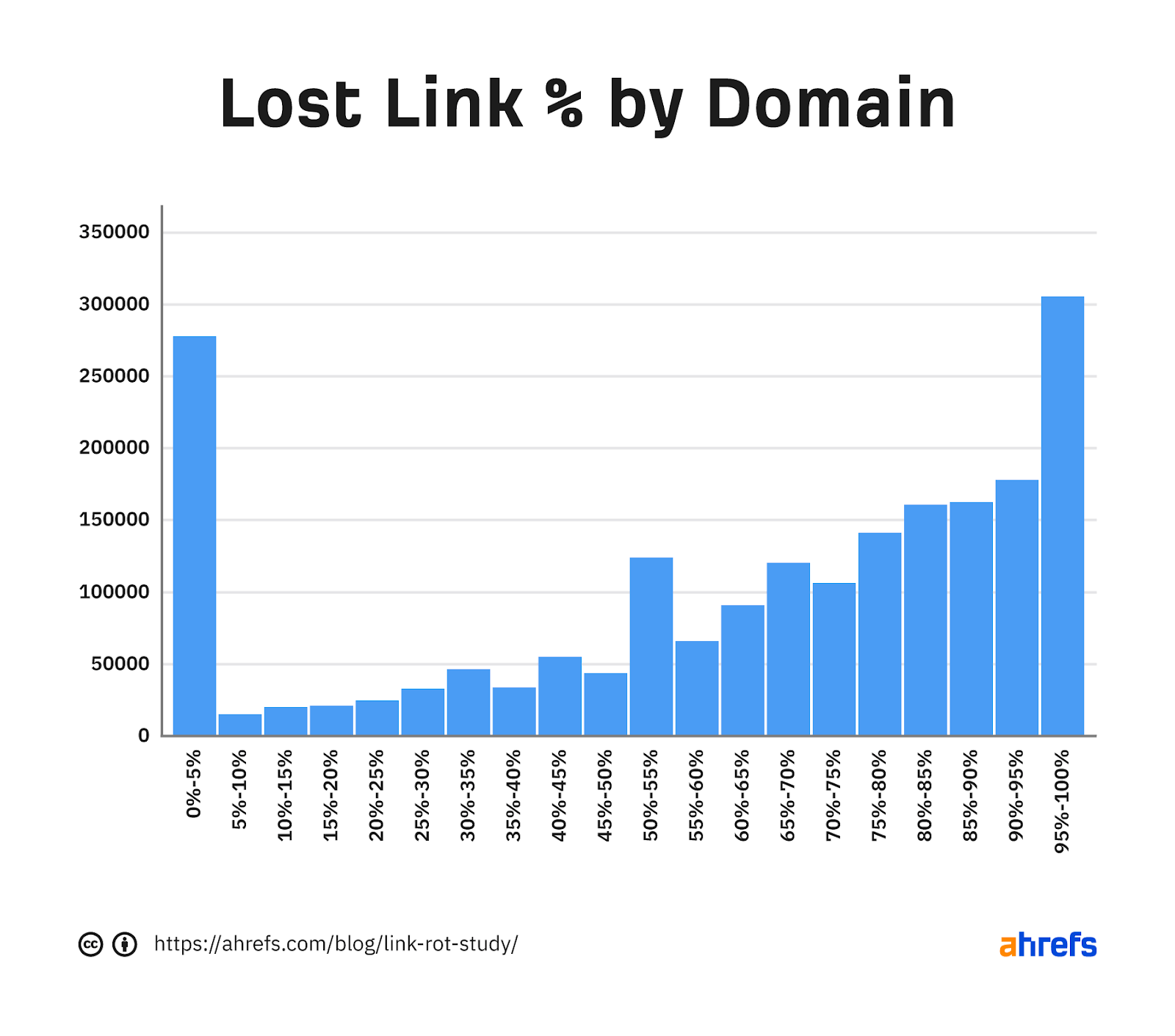
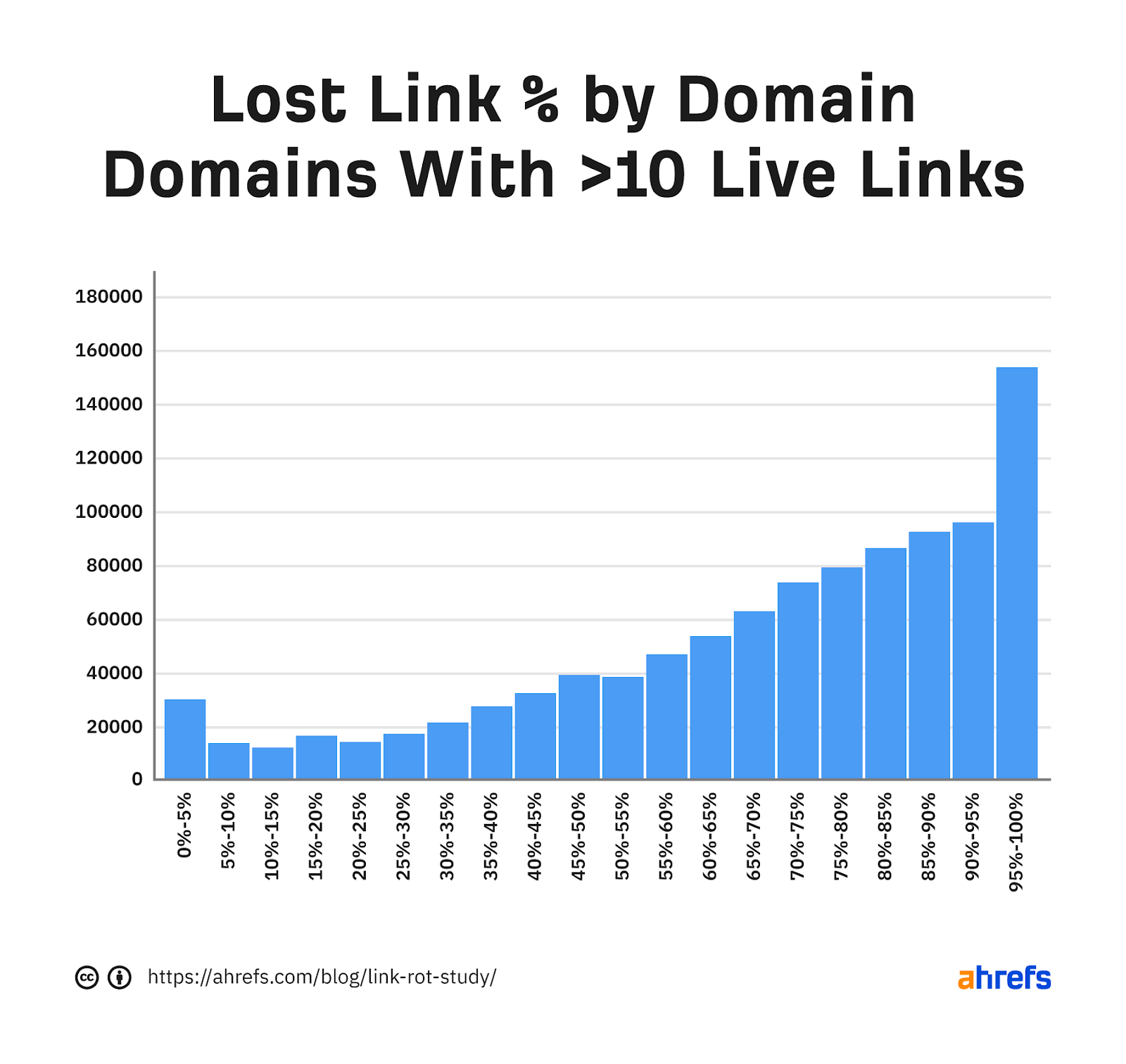
There are a lot of small sites that don’t have many lost links. If we take out the smallest sites and only look at those with more than 10 live links, you’ll see that larger sites seem to have lost quite a lot of their links.
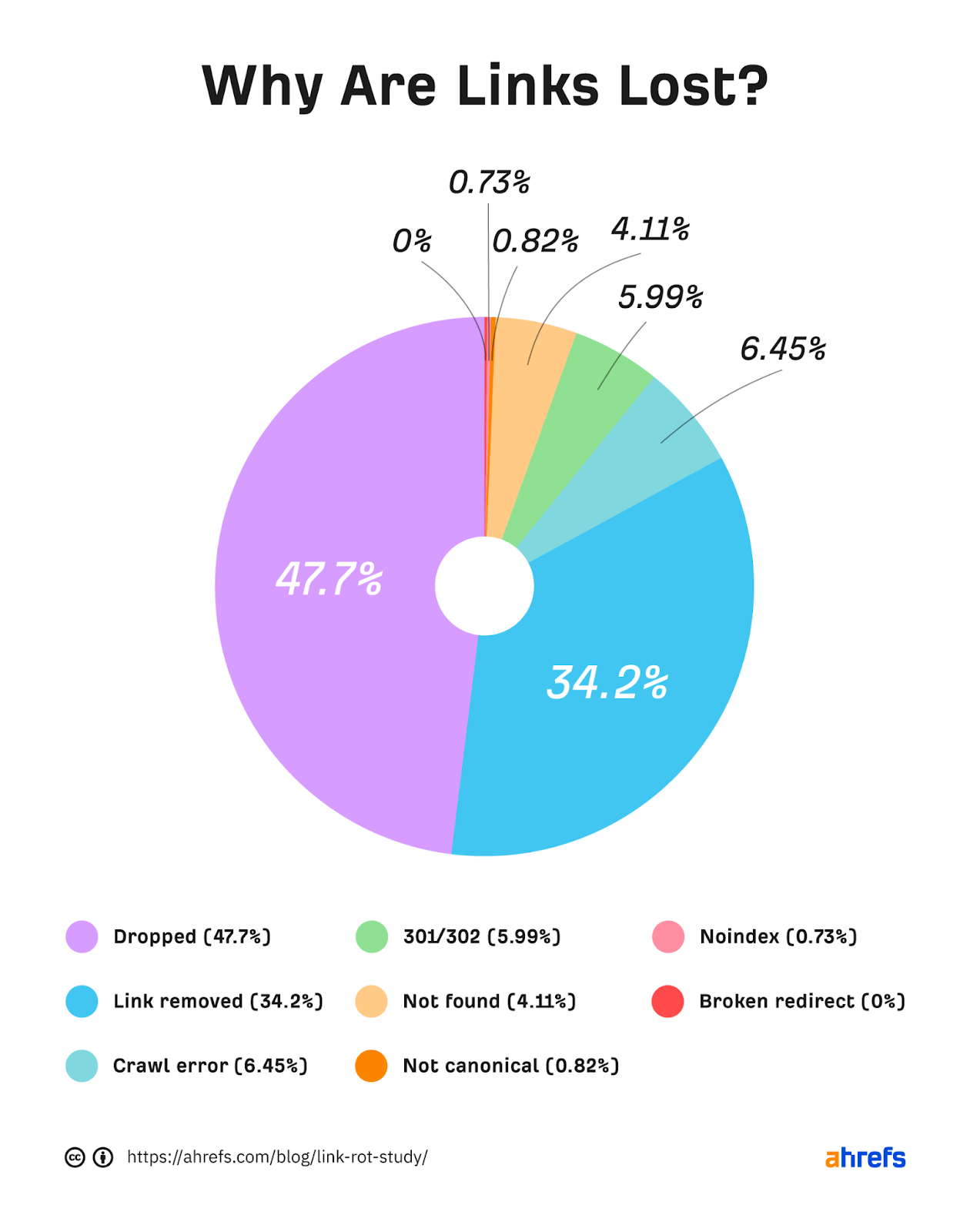
Links can be lost for many reasons. We classify lost links in different ways at Ahrefs. Here are the most common reasons that links are lost:
- Dropped (47.7%)
- Link removed (34.2%)
- Crawl error (6.45%)
- 301/302 (5.99%)
- Not found (4.11%)
- Not canonical (0.82%)
- Noindex (0.73%)
- Broken redirect (0%)
Let’s look at each of those and why they happen.
47.7% of links are from dropped pages
These pages are removed from our index for various reasons.
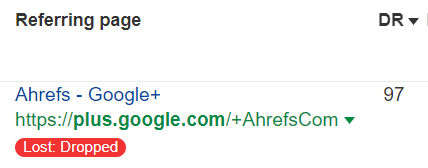
Pages may be dropped because they can’t be crawled or indexed. In some cases, a domain may not exist anymore.
34.2% of links are removed
In this case, the pages still exist; they just no longer link to you.
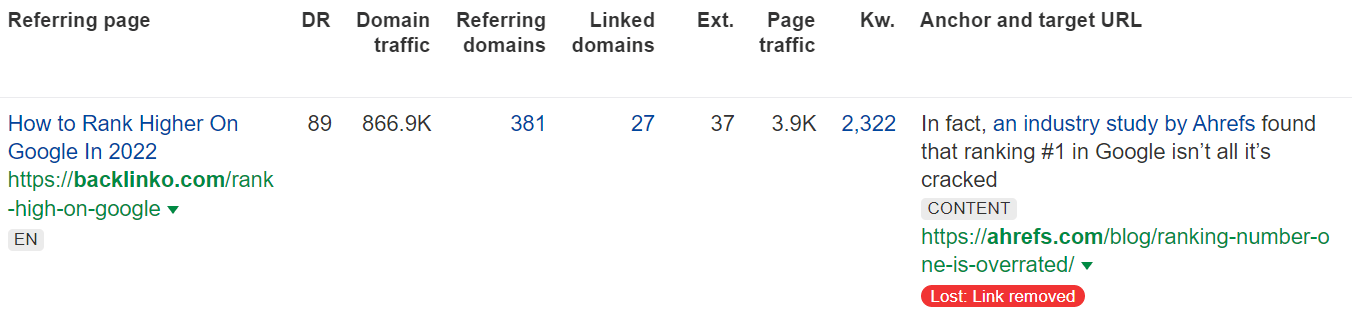
It could be that someone removed the link during a content refresh, replaced your link with a different one, or removed the link due to company policies. Another possibility is that a competitor decided to no longer link to you.
6.45% of lost links are from crawl errors
When we encounter an error while trying to crawl a page, it will be put into this bucket.
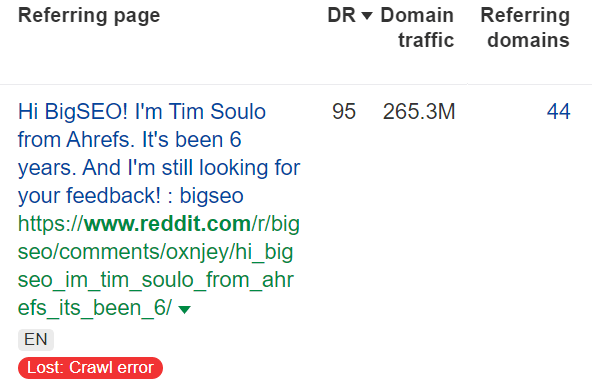
If the page is accessible when it’s crawled again and the link is still there, it will be counted as live. If the page continues to “error,” we may drop it from the index.
We chose to not count crawl errors in the total for link rot. It’s likely that a portion of these links no longer exists, but others still do.
5.99% of links are lost due to redirected pages
The page containing the link has been redirected somewhere else.

Pages change locations for all kinds of reasons. Commonly, this is the result of some kind of website migration.
4.11% of links are pages that are not found
In this case, the linking page has been deleted. The content, including the link, is missing.
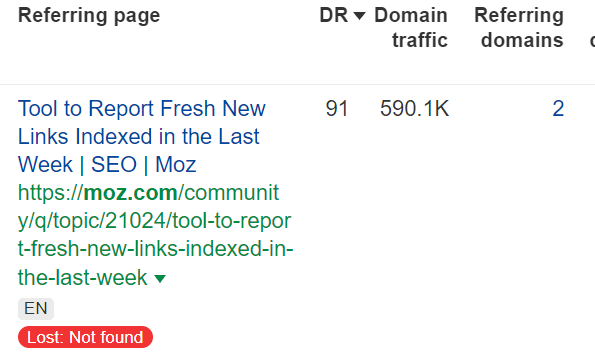
Occasionally, these pages may become live again or be redirected; in such situations, they will be added back or placed in the redirect bucket.
0.82% of links are lost because the page they were on is no longer canonical
The canonical specified by the page has changed.
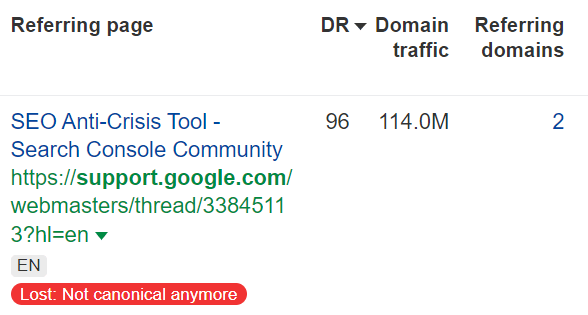
The linking page has a “rel=canonical” tag to some other location. It could be a change from HTTP to HTTPs or some kind of standardization involving trailing slashes or parameters. This is usually nothing to be worried about. The page is simply changing how it wants to be indexed. These links have just shifted locations, going from one page to another.
0.73% of links are lost because their pages are marked “noindex”
The linking page is marked “noindex,” so we don’t count the links from it.
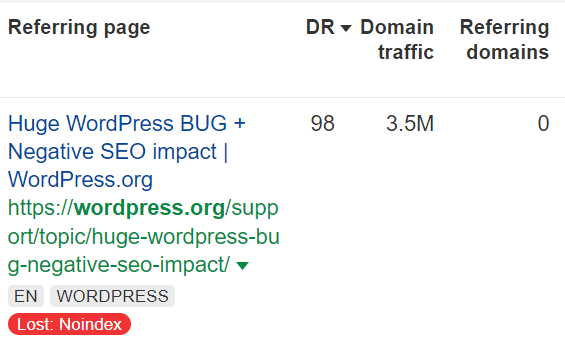
We did not count pages marked as noindex in the numbers for link rot. The link technically exists, but the page it’s on won’t be found in search engines and won’t pass any value.
A small number of links are lost due to broken redirects
In this case, we saw multiple redirects in a chain before. Now one of those redirects is broken. The link is, thus, kind of disconnected from the target.

This happens if:
- The redirect chain is broken – If any of the pages in the redirect chain fails to respond, it gets reported as a lost link.
- The redirect no longer exists (or is changed) – Let’s say you had a link from Site A → Site B, but the link was first redirected through one or more other URLs (e.g., Site A → Site C → Site B). If the linking site swapped this link out so that it linked directly (rather than going through a redirect chain), it would be reported as a lost link. The same applies if the final URL of the redirect is changed to redirect elsewhere.
What can you do about link rot?
A lot of the links you obtain may be lost over time. One way you can possibly get some of them back is with link reclamation.
In many cases, your old URLs have links from other websites. If they’re not redirected to the current pages, then those links are lost and no longer count for your pages. It’s not too late to do these redirects, and you can quickly reclaim any lost value. Think of this as the fastest link building you will ever do.
Here’s how to find those opportunities:
I usually sort this by “Referring domains.”
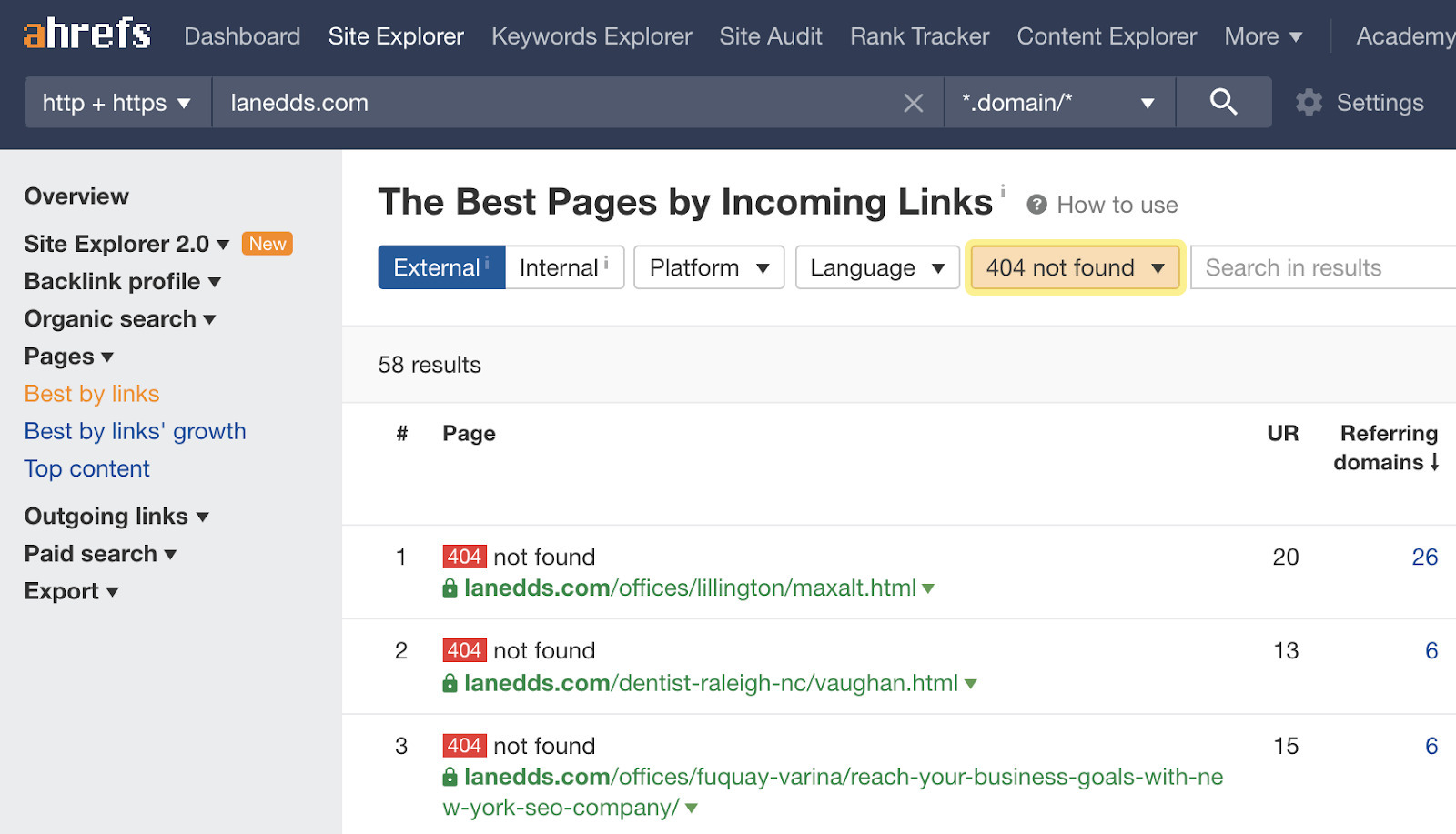
You can even use link rot to your advantage. Broken link building is a tactic that involves finding resources in your niche that are no longer live, then reaching out to site owners and letting them know about a resource you have that can replace the broken link.
Want to know how to do this for your site? Our head of content, Joshua Hardwick, has you covered with a process-oriented guide to broken link building.
Another way to help with link rot is to fix broken links on your own website. These are easily identified in the Site Audit Links report. Just remove the links or update the reference to a relevant page that exists.
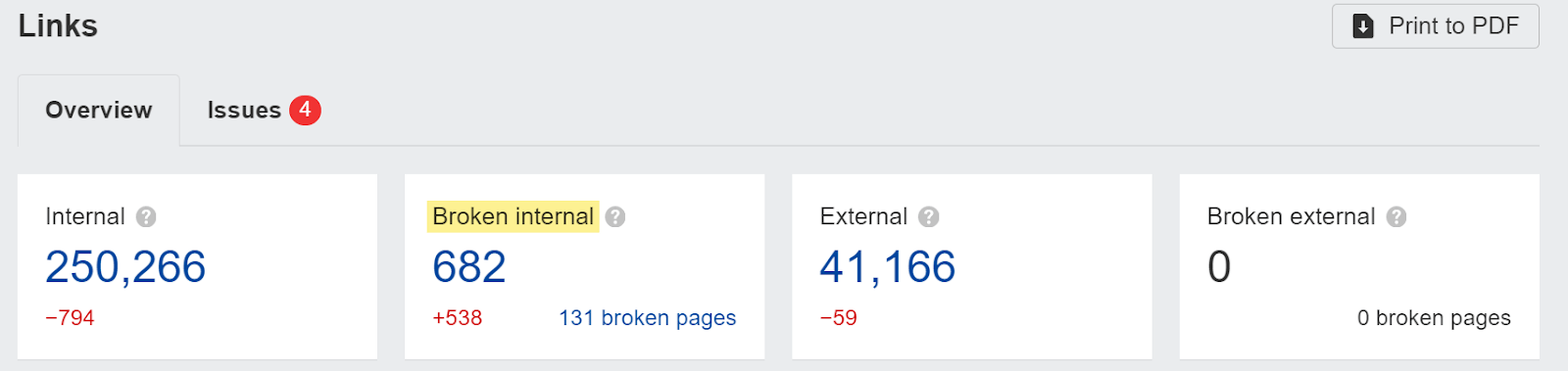
You may also want to fix broken links from your site that point to other sites. I have trouble arguing for this for SEO and, generally, will deem it as a website health and maintenance task that is of pretty low priority.
However, you can argue that clicking these links is bad for user experience. Accordingly, you can prioritize the links that are more often clicked.
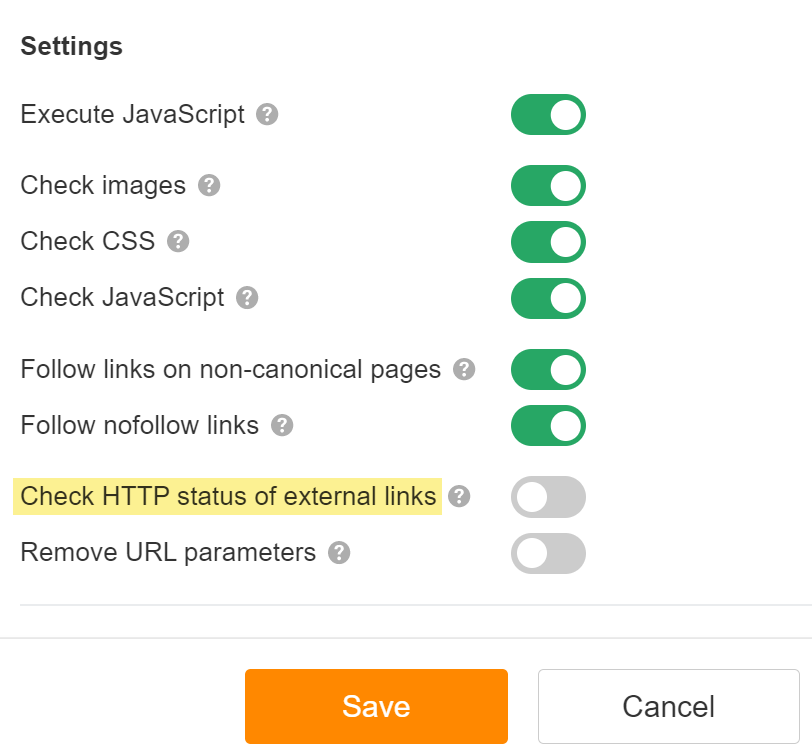
The list of broken links to external pages can also be found in the Links report. If you see zero broken external links as I do, it’s probably because you didn’t enable “Check HTTP status of external links” in your Site Audit crawl settings.
Final thoughts
Some companies and technologies have tried to help with link rot. Many of these solutions don’t really solve the problem of broken links or a changing web. Instead, they rely on archiving what was on the web so it can still be seen. For example, the Internet Archive has a Chrome extension that will show archives of pages if they’re broken.
Similarly, the CDN Cloudflare has an Always Online option that will first look for its own archived copy of a page that’s offline. But if that doesn’t exist, it will pull the most recent version from the Internet Archive.
If you use Brave browser, a broken page will have a message that lets you check for an archived version at archive.org.
The Law Library of Congress implemented an external archiving solution for the problem of link and reference rot in its legal research reports.
As always, message me on Twitter if you have any questions.
Source: ahrefs.com, originally published on 2022-04-29 01:40:30

![How to Successfully Use Social Media: A Small Business Guide for Beginners [Infographic]](https://b2webstudios.com/storage/2023/02/How-to-Successfully-Use-Social-Media-A-Small-Business-Guide-85x70.jpg)



![How to Successfully Use Social Media: A Small Business Guide for Beginners [Infographic]](https://b2webstudios.com/storage/2023/02/How-to-Successfully-Use-Social-Media-A-Small-Business-Guide-300x169.jpg)

Recent Comments